
1.1 数据的时代
数据的分类:
- 结构化数据:即有固定格式和有限长度的数据。例如填的表格就是结构化的数据,姓名:小明,学号:1234567,班级:一年三班,性别男,这都叫结构化数据
- 非结构化的数据:非结构化的数据越来越多,就是不定长、无固定格式的数据,例如网页,图片文件,有时候非常大,有时候很小,例如:语音,视频都是非结构化的数据
- 半结构化数据:XML或者HTML的格式的数据
1.2 数据库的发展史
- 萌芽阶段:文件系统
- 使用磁盘文件来存储数据
- 初级阶段:第一代数据库
- 出现了网状模型、层次模型的数据库
- 中级阶段:第二代数据库
- 关系型数据库和结构化查询语言
- 高级阶段:新一代数据库
- “关系-面向对象”型数据库
文件管理系统的缺点:
- 编写应用程序不方便
- 不支持对文件的并发访问
- 无安全控制功能
- 难以按用户视图表示数据
- 数据间联系弱
- 数据冗余不可避免
- 应用程序依赖性
1.3 DBMS 数据库管理系统
- Database:数据库database是数据的汇集,它以一定的组织形式存与存储介质上
- DBMS:Database Management System,是管理数据库的系统软件,它实现数据库系统的各种功能。是数据库系统的核心
- DBA:Database Administrator,负责数据库的规划、设计、协调、维护和管理等工作
- Application:应用程序,指以数据库为基础的应用程序
数据库管理系统的优点:
- 程序与数据相互独立
- 保证数据的安全、可靠
- 最大限度地保证数据的正确性
- 数据可以并发使用并能同时保持一致性
- 互相关联的数据的集合
- 较少的数据冗余
数据库管理系统的基本功能:
- 数据定义
- 数据处理
- 数据安全
- 数据备份
1.4 各种数据库管理系统
1.4.1 层次数据库
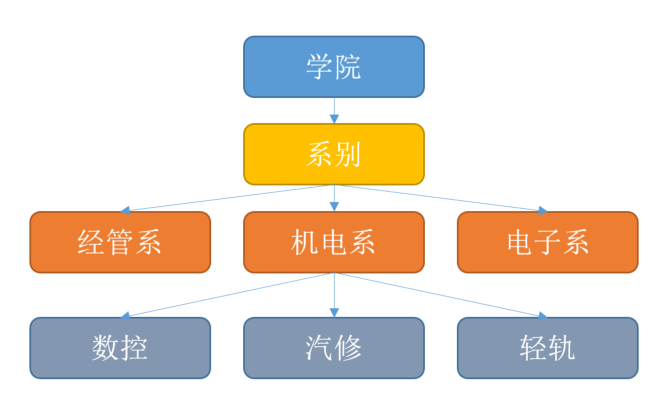
分层结构由IBM在20世纪60年代开发,并在早期大型机DBMS中使用。记录的关系形成了一个树状模型。这种结构简单,但缺乏灵活性,因为这种关系仅限于一对多关系。
代表数据库:IBM IMS(信息管理系统)
1.4.2 网状数据库
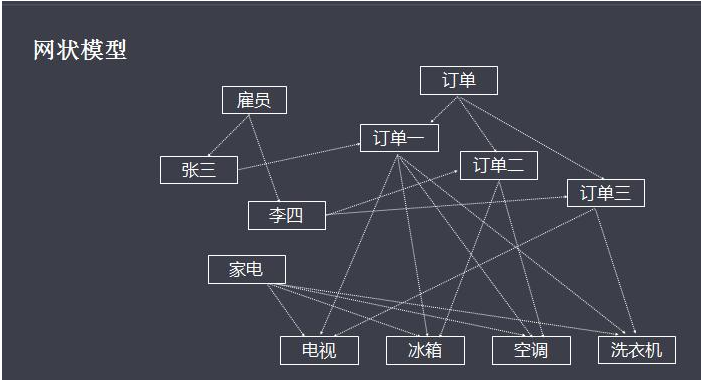
1964年通用电气GE公司的Charles Bachman成功地开发出世界上第一个网状数据库IDS(集成数据存储),IDS具有数据模式和日志的特征,只能在GE主机运行
1.4.3 RDBMS 关系型数据库
关系模型最初由IBM公司的英国计算机科学家埃德加·科德(Edgar F. Codd)于1969年描述,1974年,IBM开始开发系统R,这是一个开发RDBMS原型的研究项目。然而,第一个商业上可用的RDBMS是甲骨文,于1979年由关系软件(现为甲骨文公司)发布
1.4.3.1 关系型数据库相关概念
- 关系:关系就是二维表,其中:表中的行、列次序并不重要
- 行row:表中的每一行,又称为一条记录 record
- 列column:表中的每一列,称为属性,字段,域 field
- 主键:Prinmary key:PK,一个或多个字段的组合,用于惟一确定一个记录的字段,一张表只有一个主键
- 惟一键Unique key:一个或多个字段的组合,填入的数据必须能在本表中唯一标识本行;允许为NULL,一个表可以存在多个
- 域domain:属性的取值范围,如:性别只能是“男”和“女”两个值,人类的年龄只能0-150
1.4.3.2 常用关系型数据库
- MySQL:MySQL, MariaDB,Percona Server
- PostgreSQL:简称pgsql,EnterpriseDB
- Oracle
- MSSQL Server
- DB2
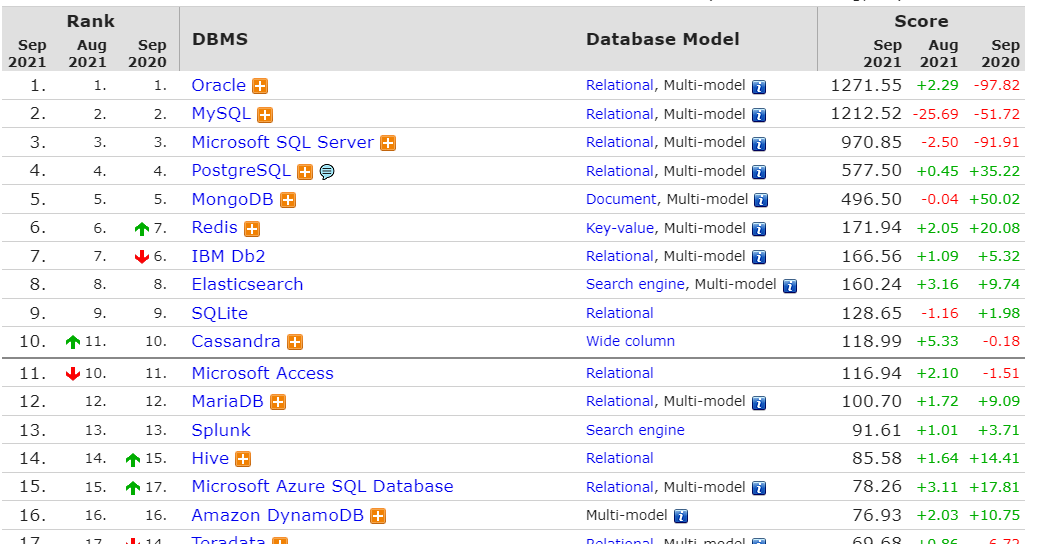
1.4.3.3 数据库排名
https://db-engines.com/en/ranking
1.5 关系型数据库理论
1.5.1 实体-联系模型E-R
- 实体Entity:客观存在并可以相互区分的客观事物或抽象事件成为实体,在E-R图中用矩形框表示实体,把实体名写在框内
- 属性:实体所具有的特征或性质
- 联系:联系是数据之间的关联集合,是客观存在的应用语义链
- 实体内部的联系:指组成实体的各属性之间的联系。如职工实体中,职工号和部门经理号之间有一种关联关系
- 实体之间的联系:指不同实体之间的联系。例如:学生选课实体和学生基本信息实体之间
- 实体之间的联系用菱形框表示
1.5.2 联系类型
- 一对一联系(1:1)
- 一对多联系(1:n):外键
- 多对多联系(m:n):增加第三张表
1.5.3 数据的操作
开发工程师CRUD(增加Create、查询Retrieve或Read、更行Update、删除Delete)
- 数据提取:在数据集合中提取感兴趣的内容。SELECT
- 数据更新:变更数据库中的数据。INSERT、DELETE、UPDATE
1.5.4 数据库规划流程
- 收集数据,得到字段
- 收集必要且完整的数据项
- 转换成数据表的字段
- 把字段分类,归入表,建立表的关联
- 关联:表和表之间的关系
- 分割数据表并建立关联的优点
- 节省空间
- 减少输入错误
- 方便数据修改
- 规范化数据库
1.5.5 数据库的正规化分析
数据库规范化,又称数据库或资料库的正规化、标准化,是数据库设计中的一系列原理和技术,以减少数据库中的数据冗余,增进数据的一致性。关系模型的发明者埃德加科德最早提出这一概念,并于1970年代初定义了第一范式,第二范式和第三范式的概念
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,不同的规范要求被称为不同规范式,各种范式呈递次规范,越高的范式数据库冗余越小
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯克范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的成为第二范式(2NF),其余范式以此类推。一般数据库只需要满足第三范式(3NF)即可
规则是死的,人是活的,所以范式是否必须遵守,要看业务需要而定
掌握范式的目的是为了在合适的场景下违反范式
- 第一范式:1NF
无重复的列,每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性,确保每一列的原子性。除去同类型的字段,就是无重复的列
说明:第一范式(1NF)是对关系模式的基本要求,不满足第一范式的数据库就不是关系型数据库
- 第二范式:2NF
第二范式必须先满足第一范式,属性完全依赖于主键,要求表中的每个行必须可以被唯一地区分,通常为表加上每行的唯一标识PK(主键),非PK的字段需要与整个PK有直接相关性
- 第三范式:3NF
满足第三范式必须先满足第二范式。属性不依赖于其它非主属性,第三范式要求一个数据表中不宝行已在其他表中已包含的非主关键字信息,非PK的字段不能有从属关系
1.5.6 SQL 结构化查询语言
SQL:Structure Query Languagge,结构化查询语言是1974年由Boyce和Chamberlin提出的一个通用的、功能极强的关系型数据库语言
SQL解释器:
- 数据存储协议:应用层协议,C/S
- S:server,监听与套接字,接收并处理客户端的应用请求
- C:client,客户端
- 客户端程序接口
- CLI
- GUL
- 应用编程接口
- ODBC:Open Database Connectivity
- JDBC:Java Data Base Connectivity